The Pütter growth model (Pütter 1920) states that growth is the result of tissue synthesis (“anabolism”) and tissue breakdown (“catabolism”), expressed in the formula:
\[dW/dt=aW^y-bW^z\] In the 1930’s, Ludwig von Bertalanffy published a series of papers (1932, 1934 and 1938. 1938 also happens to be the year he joined the Nazi party). In these, he introduced assumptions based on geometry that much simplified the solution of the Pütter model. Specifically, \(z=1\)1. This allowed him to easily recast the Pütter ODE in terms of weight as a function of time (this is the version in (2001)):
\[W_t=W_\infty(1-\exp(-K_{sp}(t-t_0)))^3\] In other words, the von Bertalanffy equation (VBGE) is a special case of the Pütter model, where catabolism is proportional to mass.
An even more special version of this model is the specialized von Bertalanffy equation (Beverton and Holt 1957; Pauly 1981; Ursin 1967). By also assuming that \(W\propto L^3\) and that \(b=2/3\), you can cast this as a model of length (which in easier to measure in a fish while on a boat):
\[L_t=L_\infty(1-\exp(-K(t-t_0)))\] And this is the version we all love and most fisheries biologists are familiar with. It’s the most common model for describing length as a function of age, very likely because it was adopted by Beverton and Holt (1957). von Bertalanffy (1957) writes:
“It appears that the ”Bertalanffy growth equation” is widely applied in international fisheries. It has been found to fit the commercially exploited fish species studied by the Fisheries Laboratory of the Ministry of Agriculture, Fisheries and Food at Lowestoft (England), with the possible exception of the hake (Wimpenny, pers. commun.)”2
Now, \(b=2/3\) stems originally from the “surface rule” (Rubner 1902), basically stating that since a (body) surface scales with a 2/3 power to the volume, and heat loss is proportional to the body surface, and because each each calorie must be replaced to maintain a fixed temperature (37°), “production” is proportional to \(W^{2/3}\). This doesn’t apply to ectotherms, such as fish, and in those cases the 2/3 exponent is argued to be close to the exponent of standard metabolic rate (even though we know now it’s closer to 0.8 (e.g., Clarke and Johnston 1999; Jerde et al. 2019; Lindmark, Ohlberger, and Gårdmark 2022). Or, as Pauly suggests in his Gill-Oxygen Limitation Theory (GOLT): the exponent \(y\) reflects the scaling of gill surface area in relation to weight, such that as ectotherms growh in size, they increasingly struggle to meet oxygen demands which scale in proportion to mass.
Ok, ok, enough background. The point is this: sometimes you want the parameters \(a\) and \(b\) rather than \(W_\infty\), \(t_0\), and \(K_{sp}\). You can convert between them though; \(K_{sp}=b/3\) and \(W_\infty=(a/b)^{1/(1–y)}\)(Essington, Kitchell, and Walters 2001). But note! This is only legal when you make the assumptions above! And you may not always want that. Maybe you want to estimate \(a\) and \(b\) from data instead. And why not \(y\) and \(z\) when you are at it? Maybe you don’t buy the arguments for the mechanistic basis of these parameters and want to take an empirical approach to fitting the Pütter model. Maybe you want to extend or modify the Pütter model, as in e.g., Marshall & White (2019) or Thunell et al., (n.d.). And lastly, you may want the full uncertainty on \(a\) and \(b\) directly, e.g., via a posterior distribution.
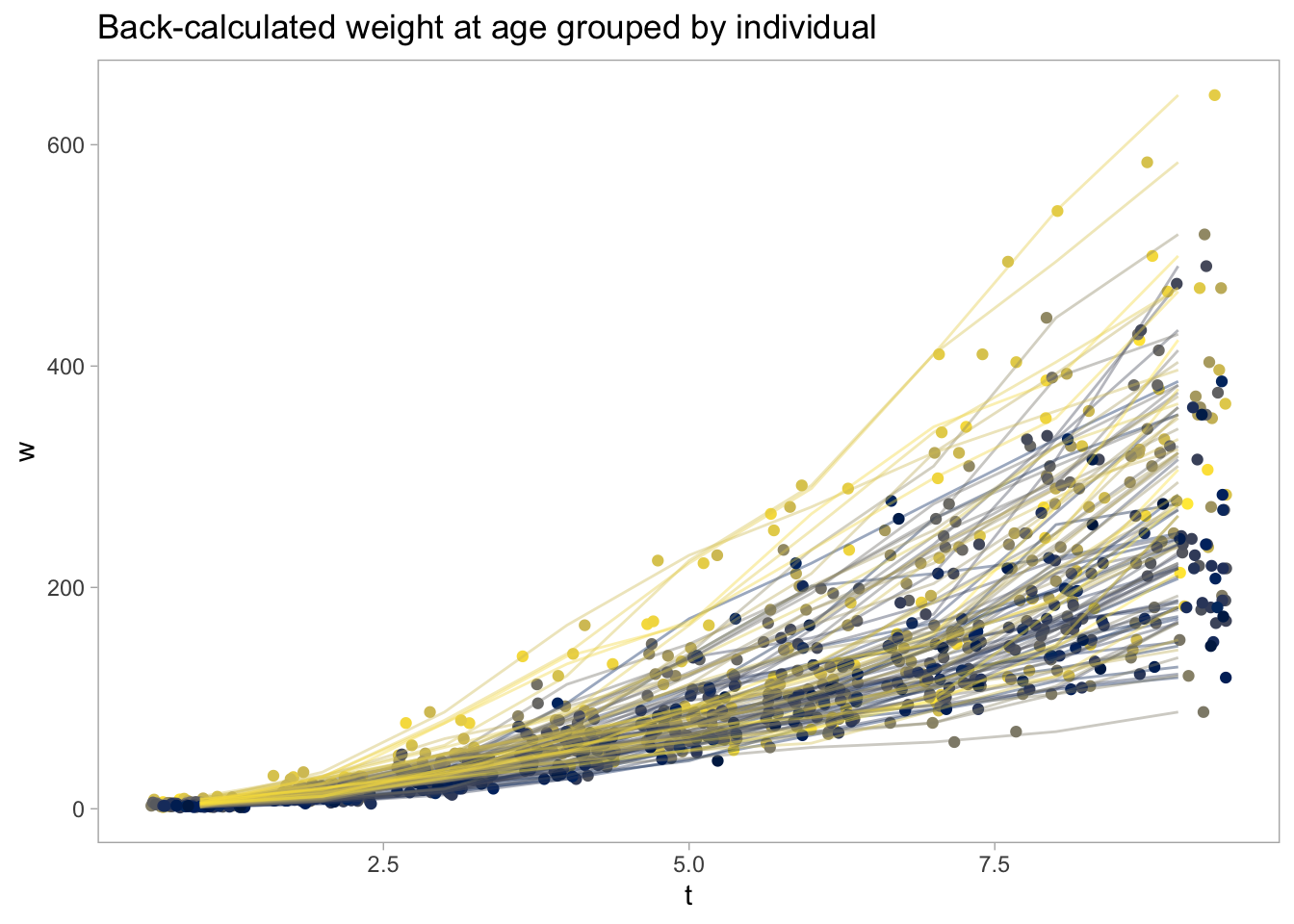
Below I show how we can fit the Pütter ODE model to data using brms. As in the last post, we will use the perch (Perca fluviatilis) data set containing back-calculated length-at-age. First we’ll load, filter, and plot the data:
# For fittingnCores <-detectCores()options(mc.cores = nCores)
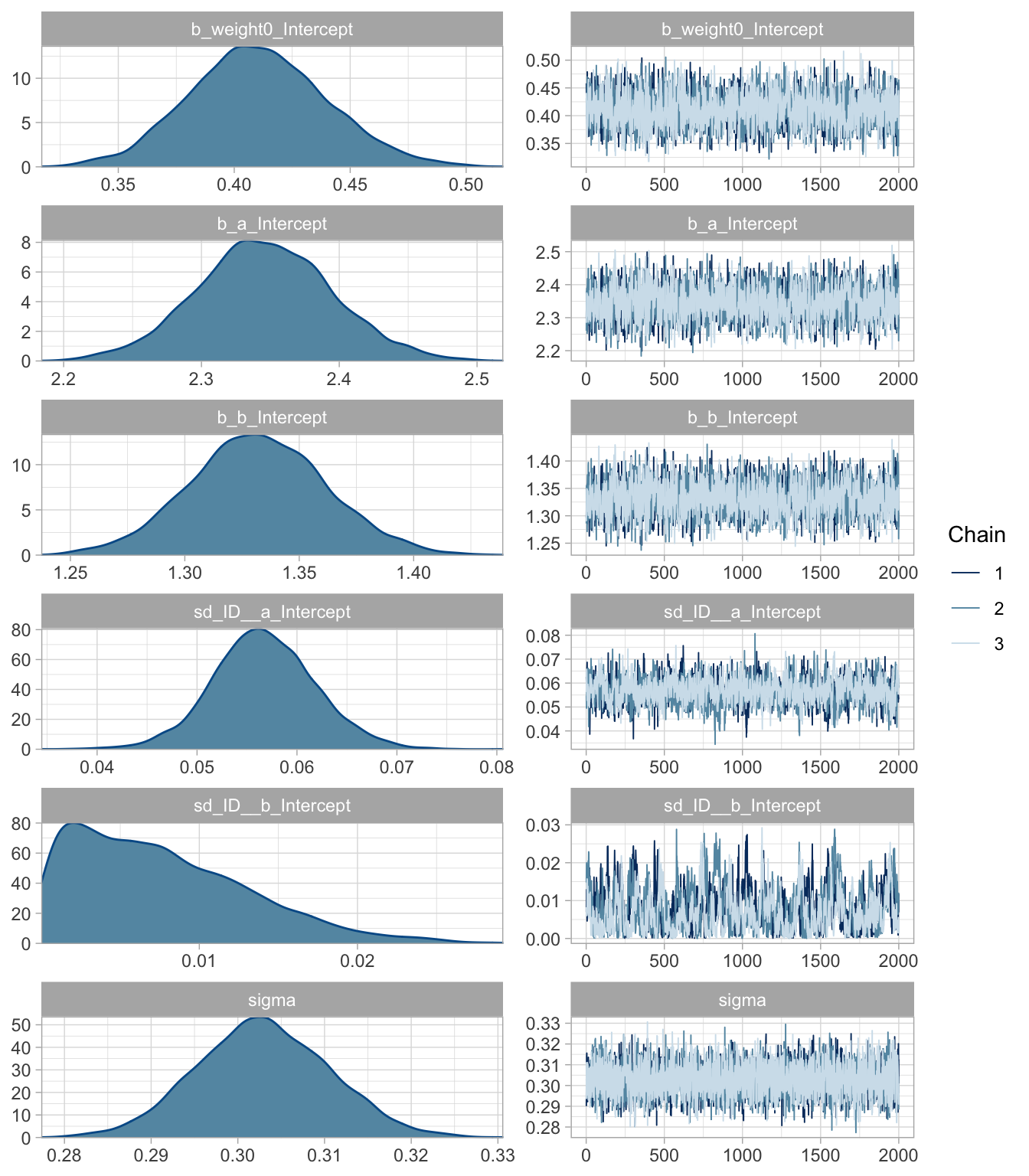
As can be seen, we have multiple observations per individual, and they either fast or slow growers. This will cause some unwanted residuals patterns unless accounted for, so we will allow the Pütter parameters to vary by individual (ID as random effect). Below I define the model. I’m using the simple exponential decay model in this Stan forum post as a template for aunivariate ODE, but I’ve also read up on the Lotka-Volterra competition model in brms from Mage’s blog and Solomon Kurz’s brms-translation of Statistical Rethinking. For speed (it still takes a solid 8h to fit this model!) I use only the first 100 individuals in the data set (there are 12786!!!), and I only estimate \(a\) and \(b\), while setting \(y=2/3\) and \(z=1\). In theory, one could add nested random effects (ID within cohorts for instance), or let the standard deviation vary with time.
A Pütter ODE model in brms
# Using this exponential decay model as a template:# https://discourse.mc-stan.org/t/new-cmdstan-ode-solvers-and-brms/24173# Simple vbge modelvb_model <-" real[] ode_vb(real t, //time real [] w, // the rates real [] theta, // the parameters real [] x_r, // data constant (not used) int[] x_i){ // data constant (not used) real dwdt[1]; // dimension of ODEs dwdt[1] = theta[1]*w[1]^(0.67) - theta[2]*w[1]^1; // growth ODE return dwdt; // returns a 3-dimensional array }// this is the function call from brms, integration of ODEs:real vb_ode(real t, real weight0, real a, real b) { real w0[1]; //one initial value real theta[2]; real w[1,1]; //ODE solution w0[1] = weight0; //initial values theta[1] = a; theta[2] = b; w = integrate_ode_rk45(ode_vb, w0, 0, rep_array(t, 1), theta, rep_array(0.0,0), rep_array(1,1), 0.00001,0.00001,100);// Return relevant values return(w[1,1]);}"vb_formula <-bf(w ~vb_ode(t, weight0, a, b), weight0 ~1, a ~1+ (1|ID), b ~1+ (1|ID),nl =TRUE)# These priors could be discussed...vb_priors <-c(prior(normal(0.00001, 1), nlpar = weight0, lb =0.00001),prior(normal(1, 1), nlpar = a, lb =0.00001),prior(normal(0.5, 1), nlpar = b, lb =0.00001),prior(cauchy(0, 10), class = sigma))
Now that all functions have been defined, we can feed that into the brm function. I use a Lognormal distribution to ensure we don’t predict negative weights.
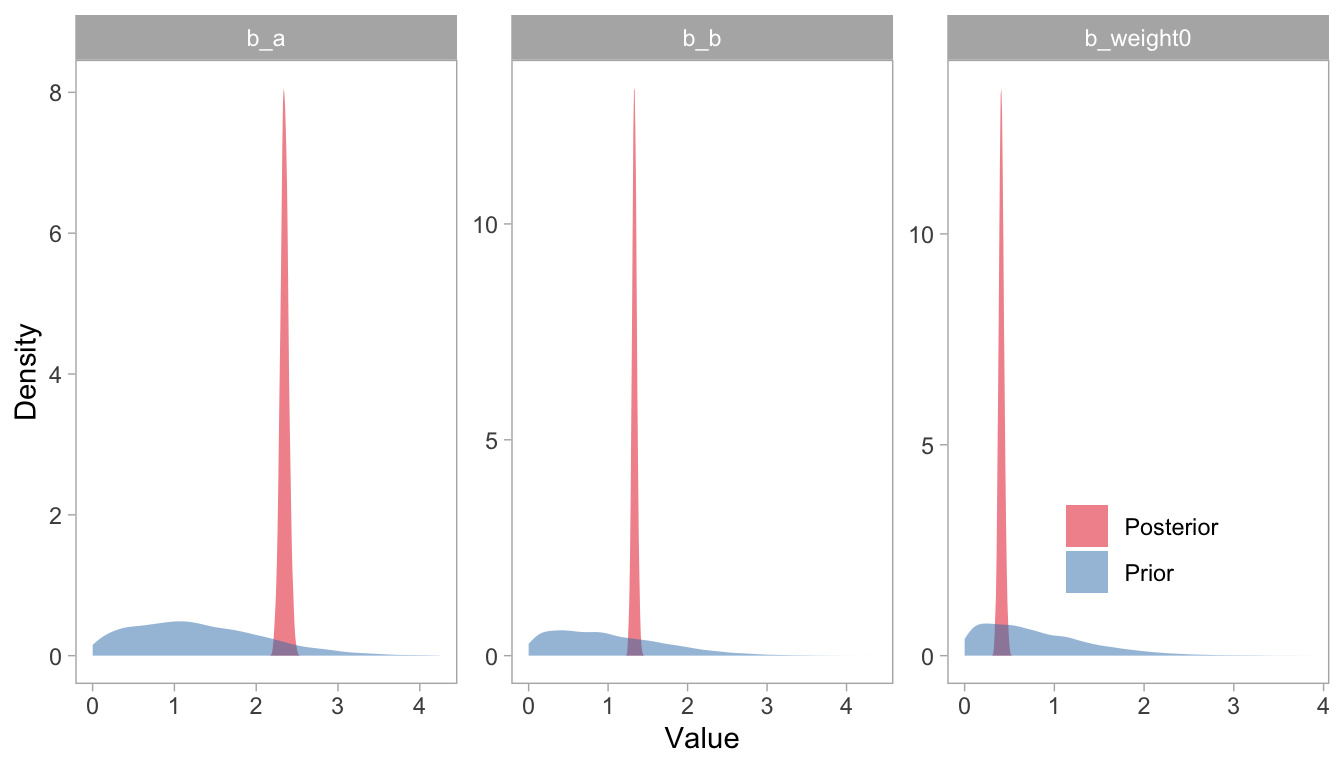
# Plot prior vs posteriorsggplot(draws) +geom_density(aes(x = value, fill = group), alpha =0.5, color =NA) +facet_wrap(~Parameter, scales ="free") +scale_fill_brewer(palette ="Set1", name ="") +theme(panel.grid.major =element_blank(),panel.grid.minor =element_blank(),legend.position =c(0.85, 0.25)) +labs(x ="Value", y ="Density")
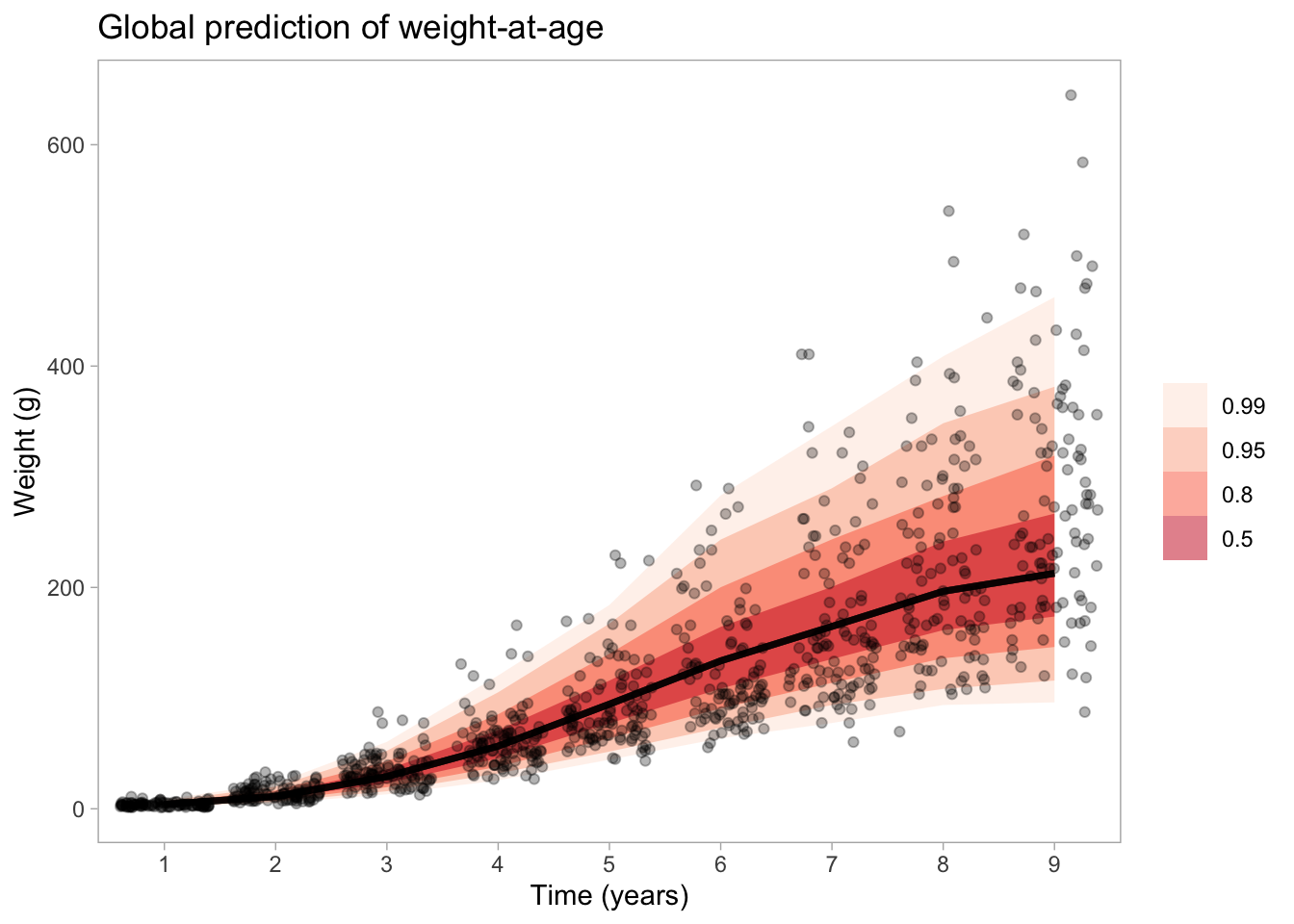
Now let’s predict from the model onto a new data (just a dataframe with time steps, representing year) and add uncertainty bands.
nd <-data.frame(t =1:max(d$t))# We now need to expose the functions to Rexpose_functions(vb_fit, vectorize =TRUE)pred <-predicted_draws(vb_fit, newdata = nd, ndraws =1000, re_formula =NA)ggplot(pred, aes(x =as.factor(t), y = w)) +stat_lineribbon(aes(y = .prediction), .width =c(.99, .95, .8, .5), alpha =0.5) +geom_jitter(data = d, aes(as.factor(t), w), height =0, alpha =0.3) +labs(y ="Weight (g)", x ="Time (years)") +scale_fill_brewer(palette ="Reds", name ="") +theme(panel.grid.major =element_blank(),panel.grid.minor =element_blank()) +ggtitle("Global prediction of weight-at-age")
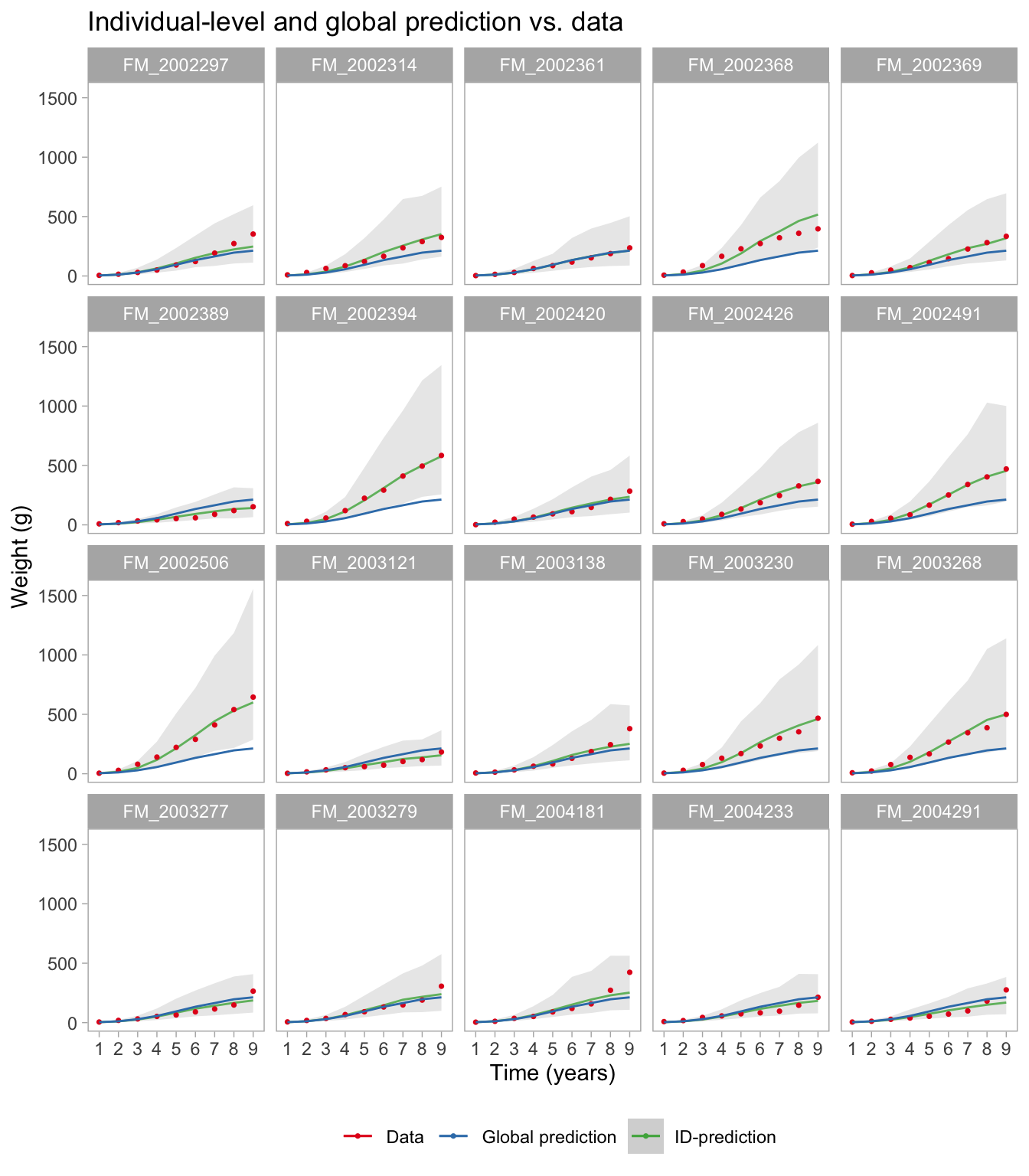
We can also explore the predictions for some of the individuals (first 20 here), and relate that to data and the global prediction. The model seems to have a reasonable global prediction and at the same time a good fit to the individual fish.
nd2 <-data.frame(expand.grid(t =1:max(d$t),ID =head(unique(d$ID), 20))) # Use 16 IDs for easier plottingpred2 <-predicted_draws(vb_fit, newdata = nd2, ndraws =1000)ggplot(pred2, aes(x =as.factor(t), y = w)) +facet_wrap(~ID) +stat_lineribbon(aes(y = .prediction, color ="ID-prediction"), .width =c(.99), alpha =0.8, size =0.5, fill ="grey90") +geom_point(data = d %>%filter(ID %in%head(unique(d$ID), 20)), aes(t, w, color ="Data"), size =0.6) +geom_line(data = pred %>%group_by(t) %>%summarise(median_pred =median(.prediction)),aes(t, median_pred, color ="Global prediction"), inherit.aes =FALSE) +scale_color_brewer(palette ="Set1", name ="") +labs(y ="Weight (g)", x ="Time (years)") +theme(panel.grid.major =element_blank(),panel.grid.minor =element_blank(),legend.position ="bottom") +guides(color =guide_legend(override.aes =list(fill =c(NA, NA, "grey80")))) +ggtitle("Individual-level and global prediction vs. data")
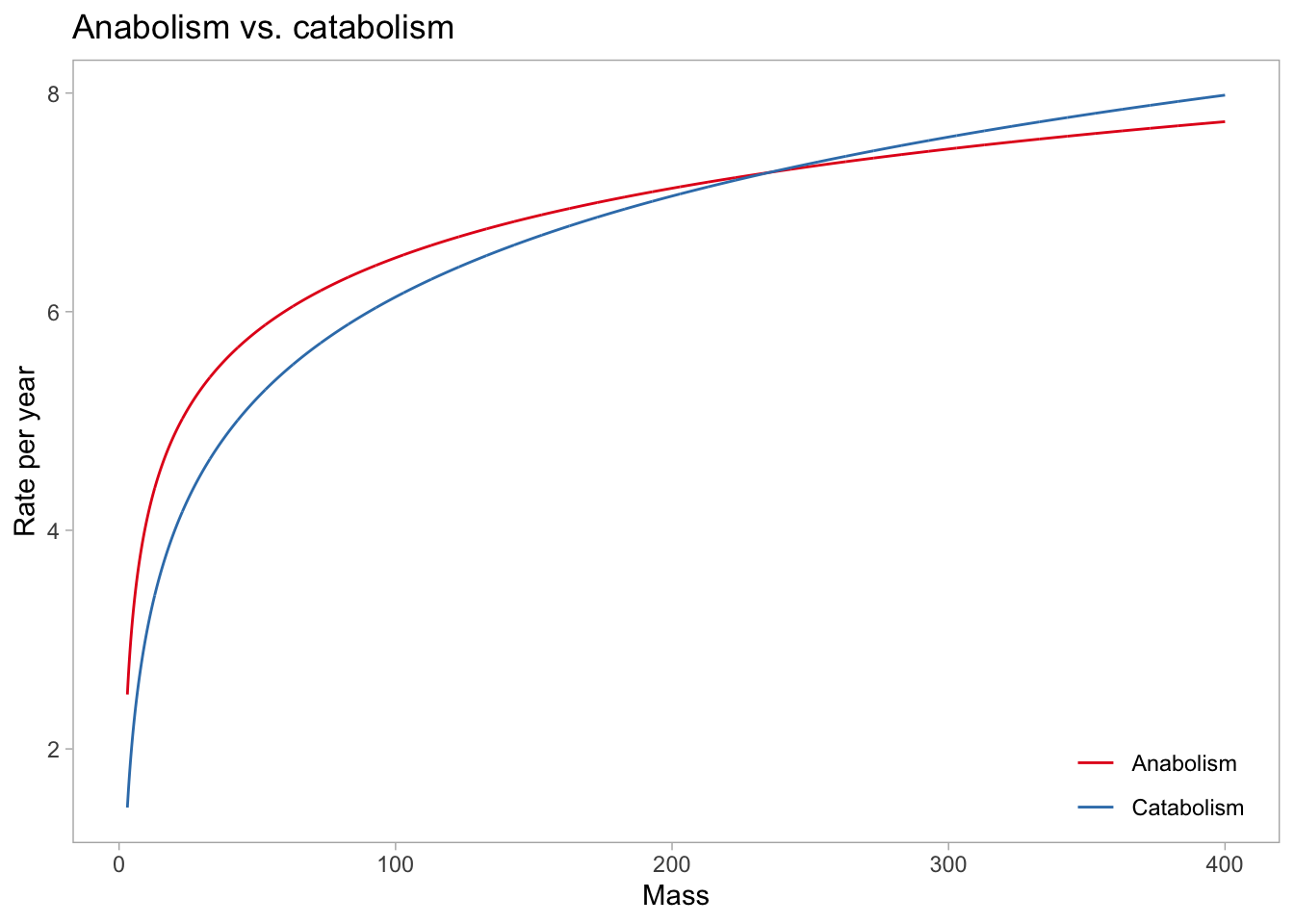
What is the \(W_\infty\)? We can visualize that by plotting the rates of anabolism and catabolism, and see where they intersect (i.e., where \(dW/dt=0\)):
pars <-summary(vb_fit)$fixed %>%rownames_to_column() %>%ungroup() %>%mutate(par =str_remove(rowname, pattern ="_Intercept")) %>% dplyr::select(par, Estimate) %>%pivot_wider(names_from = par, values_from = Estimate)data.frame(mass =log(seq(from =3, to =400, by =0.1))) %>%mutate(Anabolism = pars$a*mass^(2/3),Catabolism = pars$b*mass^1) %>%pivot_longer(c(Anabolism, Catabolism), names_to ="Rate") %>%ggplot(aes(exp(mass), value, color = Rate)) +geom_line() +labs(x ="Mass", y ="Rate per year") +scale_color_brewer(palette ="Set1", name ="") +ggtitle("Anabolism vs. catabolism") +theme(panel.grid.major =element_blank(),panel.grid.minor =element_blank(),legend.position =c(0.9, 0.1),legend.background =element_rect(fill =NA))
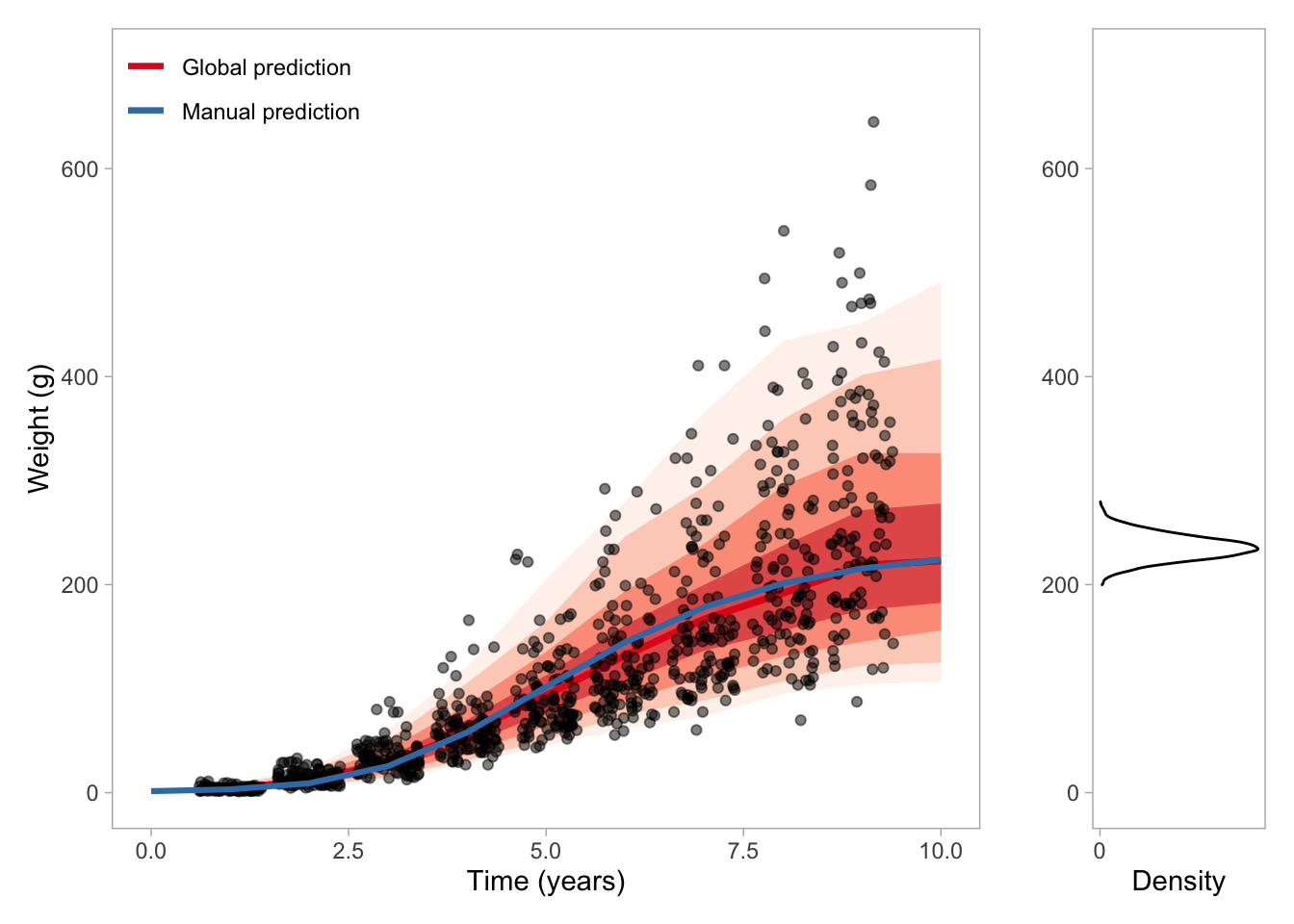
To wrap it up and link back to the motivation for this model. In my case, I want the parameters \(a\) and \(b\) with uncertainty and without having to make assumptions about isometric growth or certain scaling exponents. Because with \(a\) and \(b\) and the Pütter ODE (rhyme not intended), I can for loop change in weight for any time step (e.g., daily if I divide by 365), and I can add things like seasonality (temperature). Here I exemplify the for loop approach and compare it to data, the global predictions and the distribution of \(W_\infty\) that we get from this relation: \(W_\infty=(H/k)^{1/(1–d)}\).
max_age <-10weight_df <-data.frame(weight =c(pars$weight0, rep(NA, max_age)),age =c(0:max_age),anabolism =rep(NA, max_age +1),catabolism =rep(NA, max_age +1),dw =rep(NA, max_age +1))for(i in2:nrow(weight_df)){ anabolism <- pars$a*weight_df[i-1, "weight"]^(2/3) catabolism <- pars$b*weight_df[i-1, "weight"]^(1) dw <- anabolism - catabolism weight_df[i, "anabolism"] <- anabolism weight_df[i, "catabolism"] <- catabolism weight_df[i, "dw"] <- dw weight_df[i, "weight"] <- weight_df[i-1, "weight"] + dw}# Get new prediction with a longer time span to get the asymptotend <-data.frame(t =1:max_age)# Predict from the log-normal modelpred <-predicted_draws(vb_fit, newdata = nd, ndraws =1000, re_formula =NA)# Let's plot the data, the model prediction and the "manual" prediction using the for loops and our parameter estimates.p1 <-ggplot(d, aes(t, w)) +stat_lineribbon(data = pred, aes(t, .prediction, color ="Global prediction"), inherit.aes =FALSE, .width =c(.99, .95, .8, .5), alpha =0.5) +geom_jitter(height =0, alpha =0.5) +geom_line(data = weight_df, aes(age, exp(weight), color ="Manual prediction"), size =1.1) +scale_color_brewer(palette ="Set1", name ="") +scale_fill_brewer(palette ="Reds", name ="") +coord_cartesian(ylim =c(0, 700)) +labs(y ="Weight (g)", x ="Time (years)") +theme(panel.grid.major =element_blank(),panel.grid.minor =element_blank(),legend.position =c(0.15, 0.95),legend.background =element_rect(fill =NA)) +guides(color =guide_legend(override.aes =list(fill =NA)),fill ="none")# Get w_inf not as a fixed value but as a distribution given the posterior for a and bp2 <- post_draws <- brms::as_draws_df(vb_fit) %>%mutate(w_inf =exp((b_a_Intercept/b_b_Intercept)^(1/(1-(2/3))))) %>%filter(w_inf <700) %>%ggplot(aes(w_inf)) +geom_density() +labs(x ="", y ="Density") +coord_flip(xlim =c(0, 700)) +scale_y_continuous(breaks =c(0, 0.05)) +theme(panel.grid.major =element_blank(),panel.grid.minor =element_blank()) +NULLp1 + p2 +plot_layout(widths =c(5, 1))
Further reading on von Bertalanffy and GOLT
Global Change Biology
Lefevre, S., McKenzie, D. J., and Nilsson, G. E. 2017. Models projecting the fate of fish populations under climate change need to be based on valid physiological mechanisms. Global Change Biology, 23: 3449–3459.
Pauly, D., and Cheung, W. W. L. 2018. Sound physiological knowledge and principles in modeling shrinking of fishes under climate change. Global Change Biology, 24: e15–e26.
Lefevre, S., McKenzie, D. J., and Nilsson, G. E. 2018. In modelling effects of global warming, invalid assumptions lead to unrealistic projections. Global Change Biology, 24: 553–556.
Pauly, D., and Cheung, W. W. L. 2018. On confusing cause and effect in the oxygen limitation of fish. Global Change Biology, 24: e743–e744.
Trends in Ecology and Evolution
Marshall, D. J., and White, C. R. 2019. Have we outgrown the existing models of growth? Trends in Ecology & Evolution, 34: 102–111.
Pauly, D. 2019. Female Fish Grow Bigger – Let’s Deal with It. Trends in Ecology & Evolution, 34, 3
Marshall, D. J., and White, C. R. 2019. Aquatic life history trajectories are shaped by selection, not oxygen limitation. Trends in Ecology & Evolution, 34: 182–184.
References
Beverton, Raymond J. H., and Sidney J. Holt. 1957. On the Dynamics of Exploited Fish Populations. Fishery Investigations London Series 2, Volume 19.
Clarke, A, and N M Johnston. 1999. “Scaling of Metabolic Rate with Body Mass and Temperature in Teleost Fish.”Journal of Animal Ecology 68: 893–905.
Essington, Timothy E., James F. Kitchell, and Carl J. Walters. 2001. “The von Bertalanffy Growth Function, Bioenergetics, and the Consumption Rates of Fish.”Canadian Journal of Fisheries and Aquatic Sciences 58 (11): 2129–38. https://doi.org/10.1139/cjfas-58-11-2129.
Jerde, Christopher L., Krista Kraskura, Erika J. Eliason, Samantha R. Csik, Adrian C. Stier, and Mark L. Taper. 2019. “Strong Evidence for an Intraspecific Metabolic Scaling Coefficient Near 0.89 in Fish.”Front. Physiol. 10 (September): 1166. https://doi.org/10.3389/fphys.2019.01166.
Lindmark, Max, Jan Ohlberger, and Anna Gårdmark. 2022. “Optimum Growth Temperature Declines with Body Size Within Fish Species.”Global Change Biology 28 (7): 2259–71. https://doi.org/10.1111/gcb.16067.
Marshall, Dustin J., and Craig R. White. 2019. “Have We Outgrown the Existing Models of Growth?”Trends in Ecology & Evolution 34 (2): 102–11. https://doi.org/10.1016/j.tree.2018.10.005.
Pauly, Daniel. 1981. “The Relationships Between Gill Surface Area and Growth Performance in Fish: A Generalization of von Bertalanffy’s Theory of Growthl.”Meeresforschung, no. 28: 251–82.
Pütter, August. 1920. “Studien über physiologische Ähnlichkeit VI. Wachstumsähnlichkeiten.”Pflügers Arch. 180 (1): 298–340.
Rubner, M. 1902. Die Gesetze Des Energieverbrauchs Bei Der Ernährung. Berlin and Wien: Springer.
Thunell, Viktor, Anna Gårdmark, Magnus Huss, and Yngvild Vindenes. n.d. “Optimal Energy Allocation Trade-Off Driven by Size-Dependent Physiological and Demographic Responses to Warming.”Ecology n/a (n/a): e3967. https://doi.org/10.1002/ecy.3967.
Ursin, Erik. 1967. “A Mathematical Model of Some Aspects of Fish Growth, Respiration, and Mortality.”Journal of the Fisheries Research Board of Canada 24 (11): 2355–453. https://doi.org/10.1139/f67-190.
von Bertalanffy, L. 1957. “Laws in Metabolism and Growth.”The Quarterly Review of Biology 32 (3): 217–31.
Footnotes
In Pauly’s words this makes sense “because it [catabolism] consists of the spontaneous de-naturation of the proteins and other molecules contributing to that weight”(Pauly 2021). Pauly’s GOLT is another attempt to justify assumptions in the von Bertalanffy model and to argue for a mechanistic basis of it. I won’t go in on that here, but I provide references below to some interesting comments and reply papers published Trends in Ecology and Evolution and Global Change Biology between 2017 and 2019.↩︎
I’m sure someone has since succeeded in fitting a VBGE for hake!↩︎